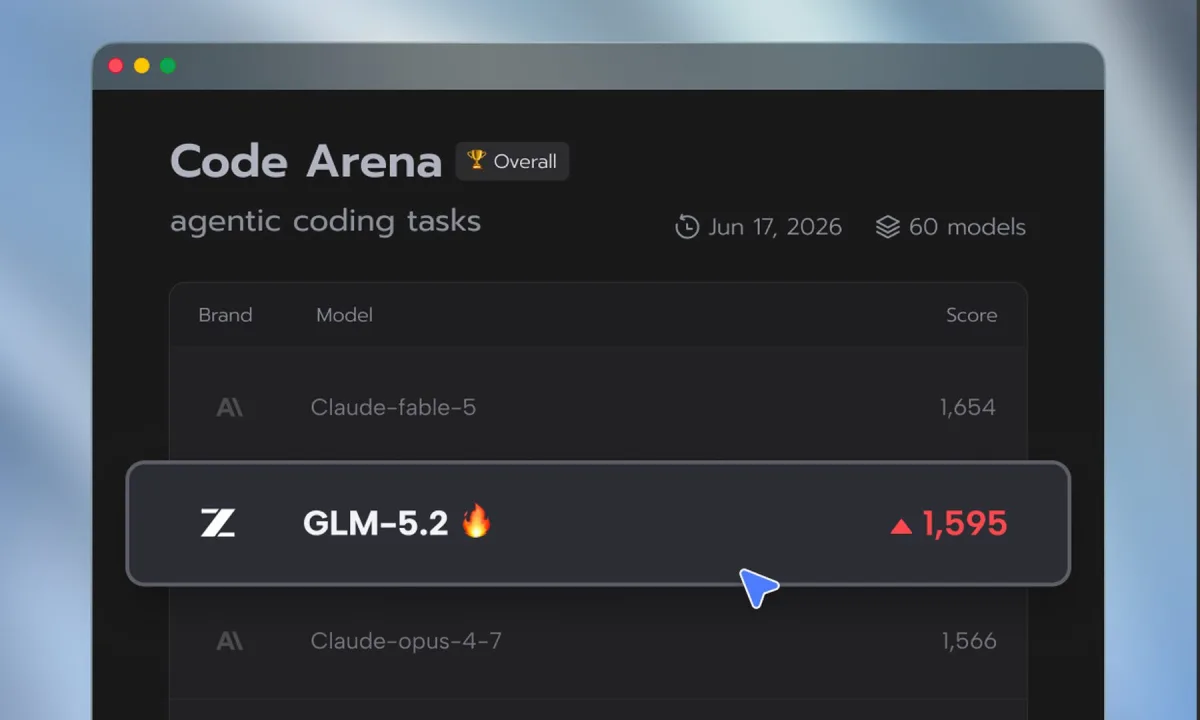
The gap in the global artificial intelligence race is closing faster than anticipated, particularly in the high-stakes realm of cybersecurity. According to a new report from The Wall Street Journal, Chinese AI startup Z.ai has developed an open-source model, Z.ai GLM-5.2, that matches the bug-finding capabilities of Anthropic’s industry-leading Mythos. For enterprise security teams and developers, this marks a significant shift; the ability to identify software vulnerabilities is no longer exclusive to heavily restricted, proprietary models from U.S. tech giants.
Researchers found that GLM-5.2 performs on par with Mythos when it comes to identifying software bugs, a capability that is becoming critical as companies race to patch vulnerabilities before hackers exploit them. According to benchmark data cited by the Journal, the Chinese model has even outperformed Claude Opus 4.8 in specific security evaluations. Furthermore, researchers noted that with additional prompting, GLM-5.2 can consistently reach Mythos-level bug-finding performance, even if it still trails Anthropic and OpenAI in broader, general-purpose reasoning tasks.
The strategic importance of GLM-5.2 lies in its open-source nature, meaning anyone can download, modify, and run the model on their own hardware without relying on a cloud provider. While this flexibility makes it highly attractive for enterprise environments, it also raises serious concerns that cybercriminals could adapt the open-weight model for offensive purposes. This development arrives at an awkward time for the U.S. AI industry, as companies like Anthropic and OpenAI have spent recent weeks restricting access to their frontier models over national security concerns, while Chinese labs race to release highly capable alternatives.
This narrowing performance gap was already the subject of a public debate among tech leaders. Recently, Elon Musk predicted that Chinese AI labs would likely catch up to Anthropic’s flagship Fable 5 by the first quarter of 2027 in terms of benchmark performance. Zhipu AI founder Tang Jie quickly pushed back against the timeline, stating that it "won't take that long" for China to close the distance.
On benchmarks, yes, but as measured by true usefulness even Q1 would be very impressive. Anthropic has rightly focused on maximizing useful intelligence, which does not show up in benchmarks, but definitely shows up in revenue.
- Elon Musk
Musk later clarified his position, arguing that achieving the same level of "true usefulness" would be a much tougher milestone than simply matching benchmark scores. However, the latest findings regarding GLM-5.2's real-world application in cybersecurity give Tang's optimism significantly more weight, proving that the AI race is no longer a comfortable lead for the United States.
The Open-Weight Security Dilemma
The democratization of Mythos-level bug-finding through open-weight models like GLM-5.2 fundamentally alters the cybersecurity landscape. While U.S. policy heavily focuses on restricting frontier models to maintain a strategic edge, the proliferation of highly capable, uncensored Chinese models means threat actors will soon have enterprise-grade vulnerability scanners running locally on their own hardware. This bypasses every safety filter and API restriction that Western AI companies have spent billions developing.
This reality forces a mandatory pivot in corporate defensive strategies. Organizations can no longer rely on the assumption that advanced AI capabilities are safely locked behind paywalls and corporate oversight. With offensive AI tools becoming decentralized and freely available, security teams must accelerate their automated patching pipelines, as the cost and time required for hackers to discover zero-day vulnerabilities have just dropped to near zero.
