"
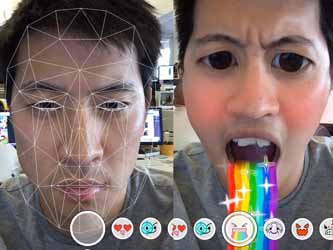
هل تجد فلاتر سناب شات سخيفة؟ تعرف على التقنيات المعقدة خلف هذه الفلاتر.
 
ماهي الرؤية الحاسوبية
كلمة السر في عمل فلاتر السناب شات هي &ldquoالرؤية الحاسوبية&rdquo، والتي يمكن تعريفها باختصار بأنها مجموعة من الخوارزميات التي تجعل الحاسب قادر على فهم الصور كما يفهمها الإنسان، وبمزيد من التفصيل نستطيع أن نقول أنّ الرؤية الحاسوبية تقوم بالاستفادة من البكسلات في الصور في تحديد الأغراض التي تتضمنها هذه الصور، ومن ثمّ ترجمتها إلى مجسمات ثلاثية الأبعاد.
تطبيقات الرؤية الحاسوبية كثيرة جدًا، ولا يمكن حصرها. على سبيل المثال الرؤية الحاسوبية تسمح للفيسبوك بمعرفة الأشخاص في الصور، وتسمح كذلك للسيارات ذاتية القيادة بالعمل وتجنب دهس الناس على الطرقات، وهي كذلك تمكن البعض من الحصول على الأنف الخاص بالكلاب في سناب شات.
خطوات عمل الفلتر
يقوم الفلتر على مجموعة من الخطوات المتلاحقة والتي يبينها المخطط التدفقي التالي الموجود ضمن ملفات براءة الاختراع:
وهذه الخطوات بالترتيب هي:
1- تلقي طلب لتعديل كائن ما (الوجه على سبيل المثال).
2- كشف أو تحديد الكائن (الوجه) أثناء عمل الفيديو.
3- توليد قائمة من سمات عنصر واحد (ولتكن العين على سبيل المثال) على الأقل من الكائن (الوجه)، هذه القائمة من السمات هي التي ستستجيب لطلب التعديل.
4-تحديد عنصر واحد (العينين) على الأقل في الكائن (الوجه).
5-ملاحقة عنصر واحد على الأقل في الكائن أثناء عمل الفيديو.
6-تبديل الإطارات في الفيديو بحيث يتم تعديل عنصر واحد على الأقل من الكائن بناءً على طلب من التعديل.
هل مازال الأمر مبهمًا؟، ليس هنالك أي مشكلة لأنّنا سنأتي على كل خطوة بشيء من التفصيل.
الخطوة الأولى: تلقي طلب لتعديل كائن ما (الوجه على سبيل المثال).
يتم تلقي طلب التعديل عندما يختار المستخدم أحد الفلاتر. الفلتر يستخدم لتعديل الوجه ككل، أو أحد العناصر التي يتكون منها الوجه. بعد أن يستقبل التطبيق طلب التعديل ينتقل مباشرةً إلى المرحلة التالية وهي مرحلة الكشف.
الخطوة الثانية: كشف أو تحديد الكائن (الوجه) أثناء عمل الفيديو.
أي كيف يستطيع الحاسب معرفة أي جزء من الصورة هو الوجه، وهذا أمر يبرع فيه الدماغ البشري بشدة. ولكن هذا ما تبدو الصورة بالنسبة للحاسب.
فإذا كان الحاسب لا يملك سوى بيانات حول القيمة اللّونية لكل بكسل في الصورة، كيف يستطيع عندها إيجاد الوجه؟ حسنًا المفتاح هو خوارزمية (Viola-Jones).
هذه الخوارزمية تعتبر أداة رائدة في الكشف عن الوجوه التي توصل إليها كل من &ldquoبول فيولا&rdquo و &ldquoمايكل جونز&rdquo، تعتمد هذه الخوارزمية بشكل أساسي على البحث عن مناطق التباين بين أجزاء الصورة المضيئة والعاتمة، وتقوم هذه الخوارزمية بمسح مستمر لبيانات الصورة وثم حساب الفروقات بين قيم بكسلات التدرج الرمادي تحت الصناديق البيضاء والصناديق السوداء، على سبيل المثال تكون قمة الأنف عادة أكثر إضاءة من المنطقة المحيطة بالأنف على كلا الجانبين. تجويف العين يكون أعتم من الجبهة، ومنتصف الجبهة يكون أكثر إضاءة من جانبيه، وهكذا كما تبين الصورة التالية:
هذه اختبارات أولية لملامح الوجه، ولكن عند إيجاد تطابقات كافية في جزء معين في الصورة تستنتج الخوارزمية مباشرةً أن هذا الجزء من الصورة يمثل الوجه. هذا النوع من الخوارزميات لن يستطيع تحديد وجهك إذا كان مائلًا أو إذا كنت تدير وجهك إلى الجانب، ولكنها دقيقة جدًا لصور الوجه الأمامية، وهذا الأمر هو ذاته التي كانت تفعله الكاميرات الرقمية لسنوات ماضية، فمن ينسى المربع الذي كانت تضعه هذه الكاميرات حول الوجوه، ومن ثم انتقل الأمر إلى الهواتف المحمولة كذلك.
لكن في سبيل وضع حمرة الشفاه الافتراضية، أو أنف وأذنيّ غزال، سيكون تطبيق السناب بحاجة ليقوم بأكثر من مجرد كشف للوجه. على التطبيق في هذا الحالة تحديد مكان كل عنصر في الوجه، فوفقًا لبراءة الاختراع يقوم التطبيق بذلك عن طريق نموذج &ldquoactive shape model&rdquo وهذا ما يقودنا إلى الخطوة الثالثة.
الخطوة الثالثة:توليد قائمة من سمات عنصر واحد (ولتكن العين على سبيل المثال) على الأقل من الكائن (الوجه)، هذه القائمة من السمات هي التي ستستجيب لطلب التعديل.
سمات العنصر هي أي أشياء خاصة به وتميّزه عن غيره، فللعين سمات خاصة بها وللأنف كذلك. في سبيل الحصول على السمات الخاصة بكل عنصر يقوم التطبيق باستخدام (نموذج الشكل المتغيّر) أو بالإنكليزية (active shape model) واختصارًا (ASM).
رأى نموذج الشكل المتغيّر (ASM) النور لأول مرة في العام 1995 في جامعة مانشستر، وطوّره كل من &ldquoتيم كوتيس&rdquo و&rdquoكريس تايلور&rdquo. (ASM) عبارة عن نموذج إحصائي لشكل الوجه (أو أي شكل آخر)، ينتجه البشر عن طريق التدريب اليدوي لتحديد حواف أجزاء الوجه، والتدريب يتم عن طريق مئات وأحيانًا آلاف العيّنات من الصور. نقصد بالتدريب اليدوي وجود مدرّب يقوم بوضع نقاط على صورة الوجه (تمثل السمات)، وهذه النقاط تكون عند العينين والأنف والشفتين وإطار الوجه وهكذا، كما يظهر في الصورة التي في الأسف، ومن ثم إعادة التنقيط مع كل الصور الأخرى.
تقوم الخوارزمية بعد ذلك بأخذ متوسط صور الوجوه المنقّطة من بيانات التدريب، ومن ثم ربطها مع الصورة من كاميرا الهاتف، ومن ثم تغيير حجمها، ومن ثم تدويرها بما يتوافق مع مكان وجهك الذي يعرفه التطبيق بشكل مسبق.
ملاحظة: نموذج الشكل المتغير يتم استعماله في العديد من التطبيقات الأخرى، كالكشف عن القطع الميكانيكية والإلكترونية وفي تحليل الصور الشعاعية كذلك.
الخطوة الرابعة: تحديد عنصر واحد (العينين) على الأقل في الكائن (الوجه).
بعد أن ولّد نموذج الشكل المتغير مجموعة من السمات لكل عنصر، يقوم بمقارنة هذه السمات مع من الصور المستخدمة في التدريب. عندها سيعرف التطبيق _على سبيل المثال _ كيف سيكون شكل أسفل الشفتين أو شكل العينين، لذلك يبحث عن الأنماط في الصورة ومن ثم موائمة النقاط لكي تتناسب معها.
أحيانًا تكون بعض النقاط خاطئة ولكن لا مشكلة؛ لأنّ النموذج يستطيع تصحيحها ومن ثم نقلها بما يتوافق مع النقاط الأخرى.
الخطوة الخامسة: ملاحقة عنصر واحد على الأقل في الكائن أثناء عمل الفيديو.
عندما يقوم التطبيق بإيجاد مكان كل أجزاء الوجه، تستعمل هذه النقاط كإحداثيات لتشكيل شبكة (قناع). هذا القناع  ثلاثي الأبعاد يستطيع الحركة، الدوران، ويمكن أن يغير أبعاده بما يتوافق مع حجم وجهك في بيانات الفيديو التي تأتي مع كل إطار وعندما يحدث ذلك يستطيع القيام بالعديد من الأمور.
الخطوة السادسة: تبديل الإطارات في الفيديو بحيث يتم تعديل عنصر واحد على الأقل من الكائن بناءً على طلب من التعديل.
وصلنا للمرحلة الأخيرة حيث يستطيع التطبيق بعد تشكيل القناع، بناء أي شكل أو صورة وربطها بهذا القناع، وبالتالي يمكن عندها تغيير شكل الوجه، أو تغيير لون العيون إضافة بعض الإكسسوارات، أو إضافة بعض الأنميشين عندما تفتح فمك أو تحرك حاجبيك.
نكتفي بالقول في النهاية أنّ هذه التكنولوجيا ليست جديدة، ولكن الجديد والثورة التي قام بها سناب شات تتمثل بالقدرة على فعل كل هذه الأمور بالزمن الحقيقي ومن خلال الهاتف المحمول. هذه المرحلة من سرعة المعالجة هي مرحلة وصلنا إليها حديثًا جدًا، وكل هذا من أجل إعطاء البشر تاج من الزهور التخيلية، ولتربح الشركة الأموال كذلك!.
هنا تكون هذه اللمحة عن عمل فلاتر سناب شات قد انتهت، وكما نوهت سابقًا أنّه لا يمكن الإحاطة بعلم عمره يفوق العشرين سنة أو يزيد من خلال مقالة واحدة ولا حتى عدة مقالات، ولكنها بداية ورؤوس أقلام لمبدأ العمل. أرجو مشاركتي من خلال التعليقات بالأمور المبهمة والغير مشروحة بالشكل الكافي التي مرّت في المقالة، ليتسنى ليّ تدارك مواطن الضعف وتطوير المقالة إلى الأفضل.
"