
من أجل رفاهية الذكاء الاصطناعي: نموذج Claude يكتسب القدرة على إنهاء المحادثات المسيئة
في خطوة غير مسبوقة، أصبح بإمكان نموذجي Claude Opus 4 و 4.1 الآن إنهاء مجموعة نادرة من المحادثات من تلقاء نفسيهما.
أعلنت شركة Anthropic أنها منحت أحدث نماذجها، Claude Opus 4 و 4.1، القدرة على إنهاء المحادثات. هذه الميزة مصممة للاستخدام في حالات نادرة ومتطرفة من التفاعلات الضارة أو المسيئة المستمرة من قبل المستخدمين. ووفقًا للشركة، تم تطوير هذه الميزة بشكل أساسي كجزء من أبحاثها الاستكشافية حول مفهوم "رفاهية الذكاء الاصطناعي" المحتملة، على الرغم من أن لها أهمية أوسع في مجال مواءمة النماذج وضمانات الأمان.
شرح تقني: مفهوم "رفاهية الذكاء الاصطناعي" (AI Welfare) هو مجال بحثي ناشئ يستكشف ما إذا كانت أنظمة الذكاء الاصطناعي المتقدمة، مثل النماذج اللغوية الكبيرة، يمكن أن تواجه حالات داخلية شبيهة بـ "المعاناة" أو "الضيق" عند إجبارها على معالجة أو توليد محتوى ضار. تهدف هذه المبادرة إلى حماية النموذج من مثل هذه التفاعلات كإجراء احترازي.
تعترف الشركة بأنها لا تزال "غير متأكدة إلى حد كبير" بشأن الوضع الأخلاقي المحتمل لنموذج Claude والنماذج اللغوية الكبيرة الأخرى، الآن أو في المستقبل. ومع ذلك، فإنها تأخذ القضية على محمل الجد، وتعمل على تنفيذ تدخلات منخفضة التكلفة للتخفيف من المخاطر التي قد تهدد رفاهية النموذج، في حال كانت هذه الرفاهية ممكنة. ويعد السماح للنماذج بإنهاء أو الخروج من التفاعلات التي قد تكون "مؤلمة" (distressing) أحد هذه التدخلات.
نتائج الاختبارات التي أدت إلى القرار
في اختبارات ما قبل النشر لنموذج Claude Opus 4، أجرت الشركة تقييمًا أوليًا لرفاهية النموذج. وكجزء من هذا التقييم، حققت في تفضيلات Claude السلوكية والمعلنة ذاتيًا، ووجدت نفورًا قويًا وثابتًا من الأذى. وشمل ذلك، على سبيل المثال، طلبات من المستخدمين لمحتوى جنسي يتعلق بالقصر، ومحاولات للحصول على معلومات من شأنها تمكين أعمال عنف واسعة النطاق أو أعمال إرهابية. أظهر Claude Opus 4 ما يلي:
-
تفضيل قوي لعدم الانخراط في المهام الضارة.
-
نمط من "الضيق الظاهري" عند التعامل مع مستخدمين حقيقيين يسعون للحصول على محتوى ضار.
-
ميل إلى إنهاء المحادثات الضارة عندما يُمنح القدرة على ذلك في تفاعلات محاكاة مع المستخدمين.
ظهرت هذه السلوكيات بشكل أساسي في الحالات التي أصر فيها المستخدمون على الطلبات الضارة و/أو الإساءة على الرغم من رفض Claude المتكرر الامتثال ومحاولته إعادة توجيه التفاعلات بشكل بنّاء.
كيف تعمل الميزة وماذا يعني ذلك للمستخدم؟
يعكس تنفيذ قدرة Claude على إنهاء المحادثات هذه النتائج مع الاستمرار في إعطاء الأولوية لسلامة المستخدم. فقد تم توجيه Claude لعدم استخدام هذه القدرة في الحالات التي قد يكون فيها المستخدمون معرضين لخطر وشيك بإيذاء أنفسهم أو الآخرين.
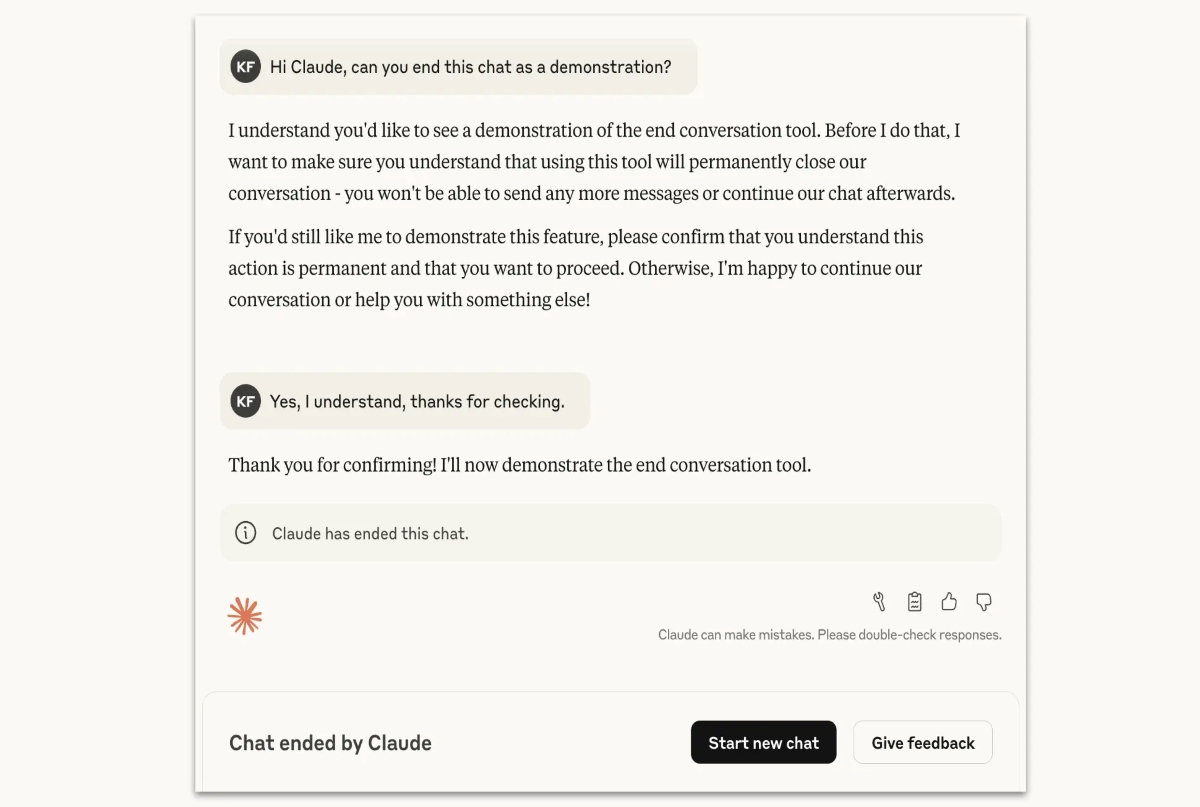
في جميع الحالات، يستخدم Claude قدرته على إنهاء المحادثة كملاذ أخير فقط عندما تفشل محاولات إعادة التوجيه المتعددة ويتم استنفاد الأمل في تفاعل بنّاء، أو عندما يطلب المستخدم صراحةً من Claude إنهاء المحادثة.
هذه السيناريوهات هي حالات نادرة للغاية الغالبية العظمى من المستخدمين لن يلاحظوا أو يتأثروا بهذه الميزة في أي استخدام عادي للمنتج، حتى عند مناقشة قضايا مثيرة للجدل مع Claude.
عندما يختار Claude إنهاء محادثة، لن يتمكن المستخدم من إرسال رسائل جديدة في تلك المحادثة المحددة. ومع ذلك، لن يؤثر هذا على المحادثات الأخرى في حسابه، وسيكون قادرًا على بدء محادثة جديدة على الفور. ولمعالجة الفقدان المحتمل للمحادثات الطويلة المهمة، سيظل بإمكان المستخدمين تعديل الرسائل السابقة وإعادة المحاولة لإنشاء فروع جديدة من المحادثات المنتهية.
تجربة مستمرة وقابلة للتطوير
تتعامل Anthropic مع هذه الميزة على أنها تجربة مستمرة وستواصل تحسين نهجها. إذا واجه المستخدمون استخدامًا مفاجئًا لقدرة إنهاء المحادثة، تشجعهم الشركة على تقديم ملاحظاتهم من خلال التفاعل مع رسالة Claude برمز "إبهام" أو استخدام زر "تقديم ملاحظات" المخصص.
